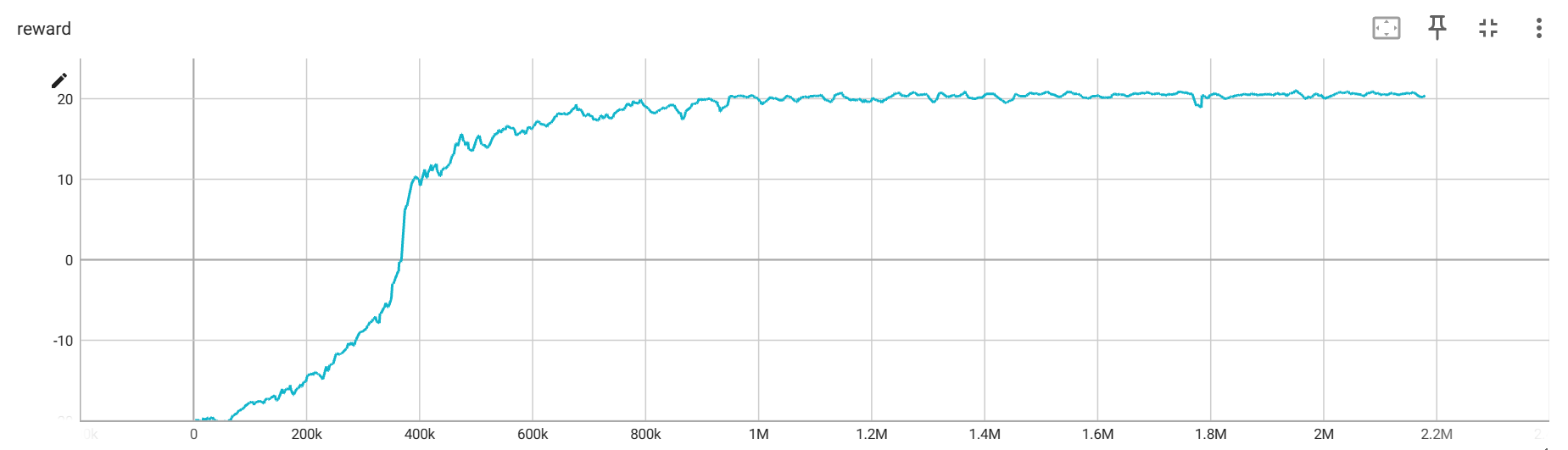
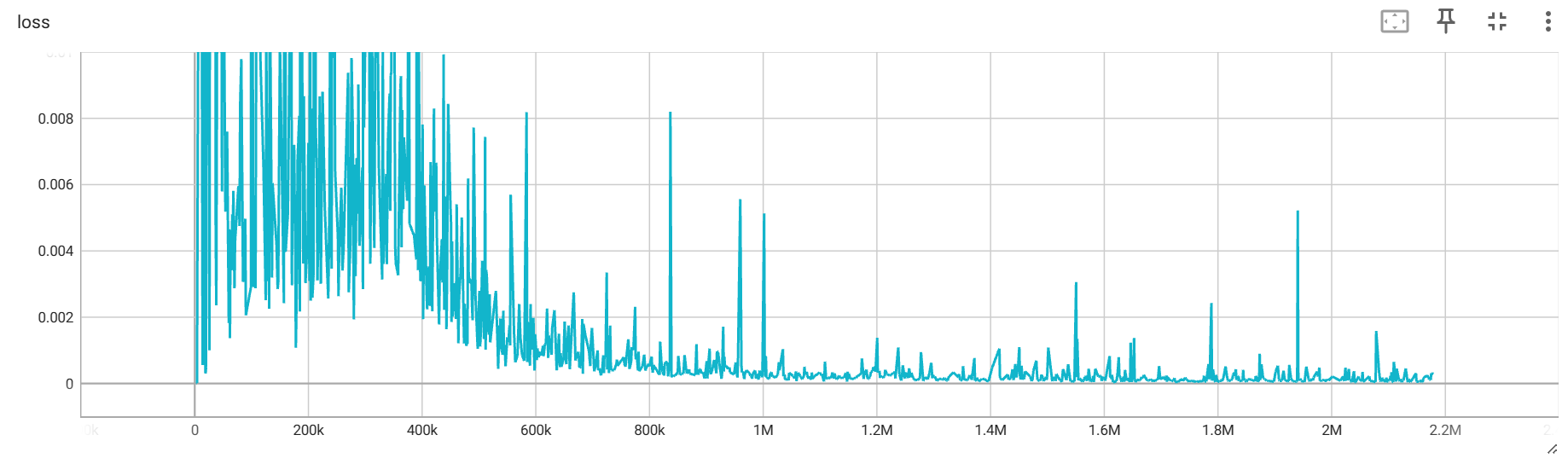
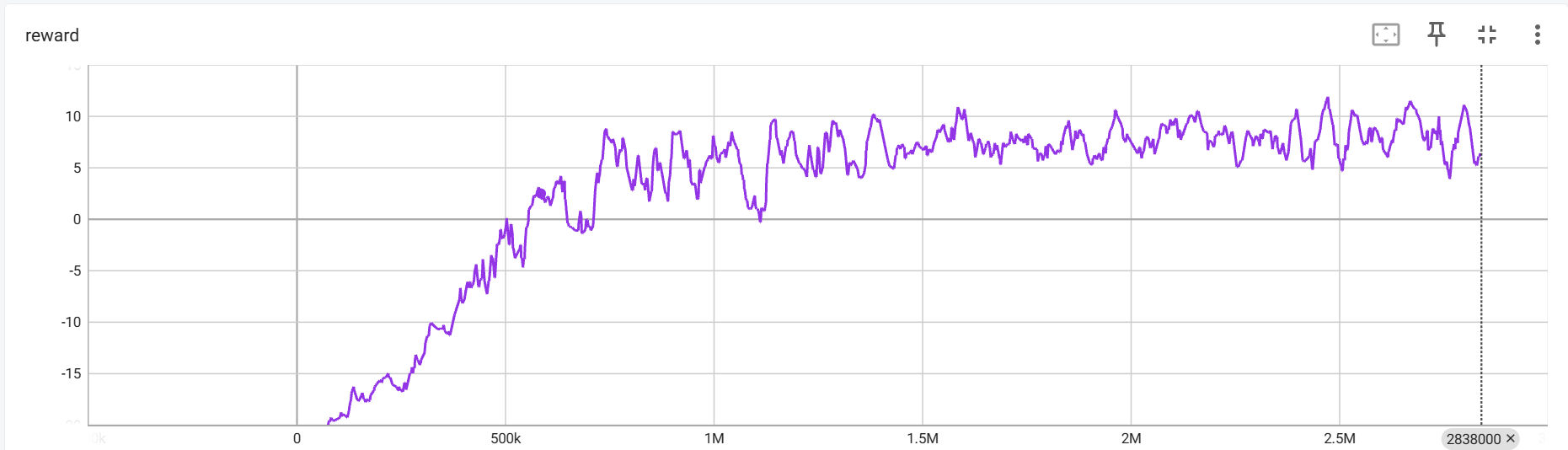
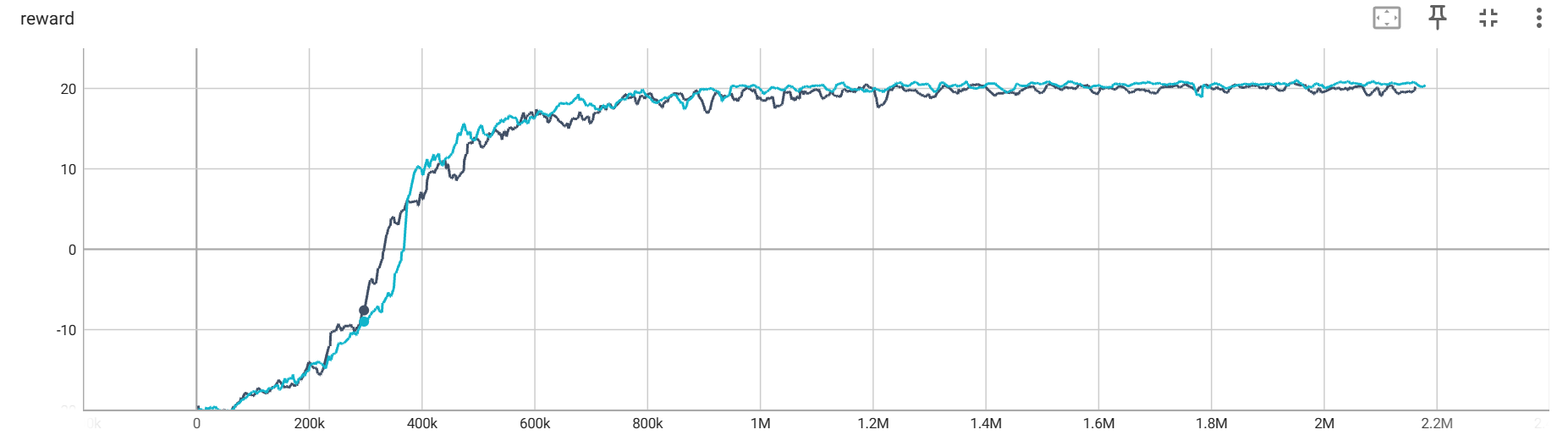
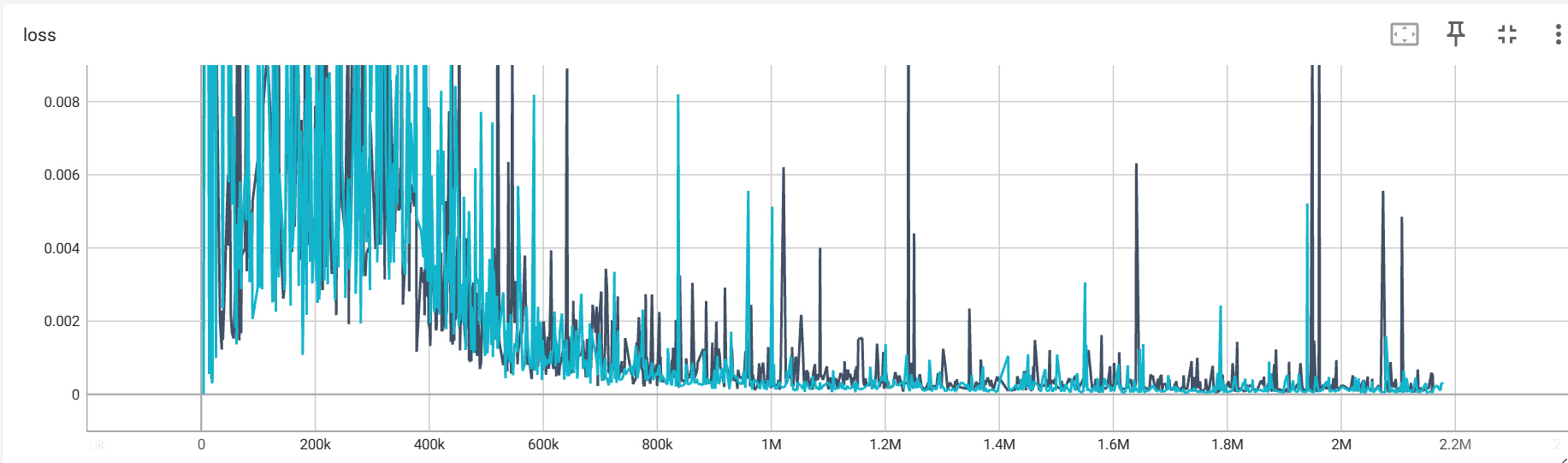
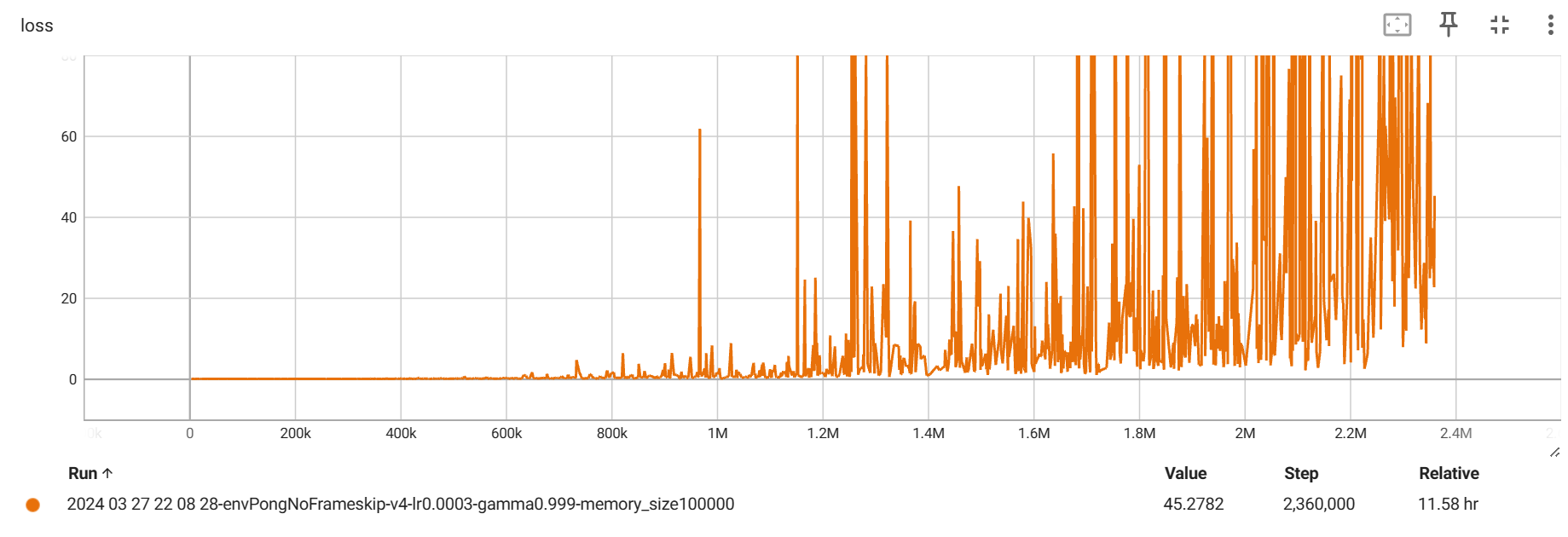
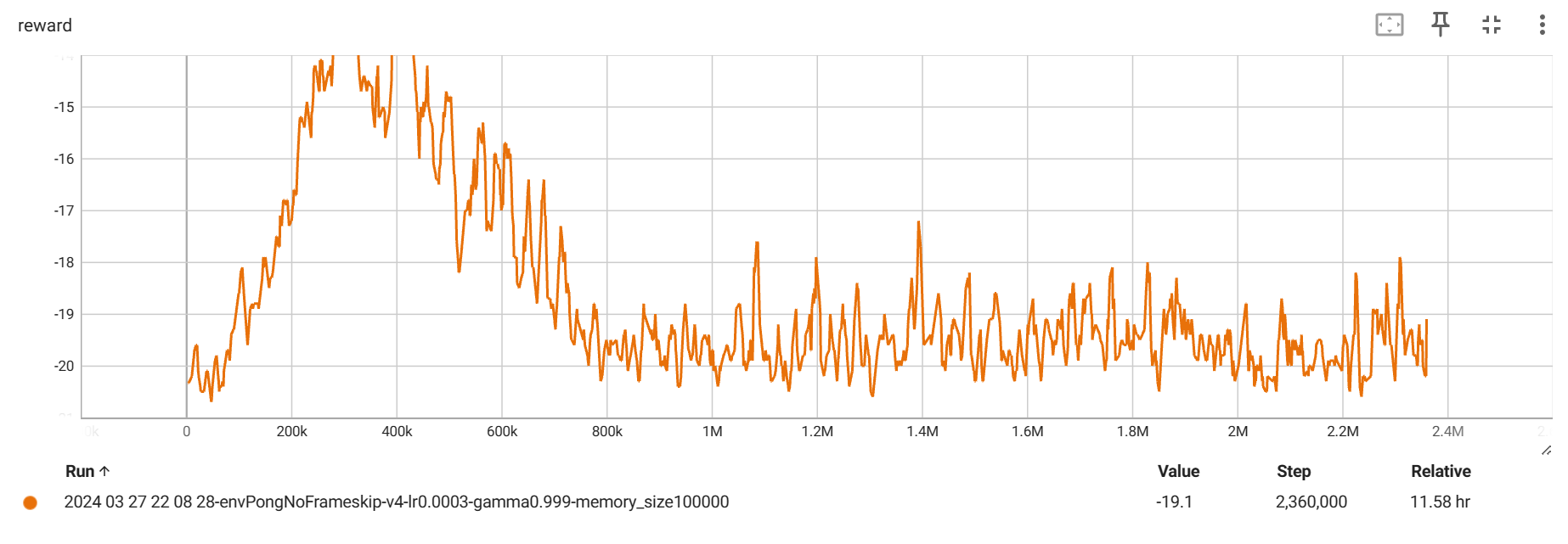
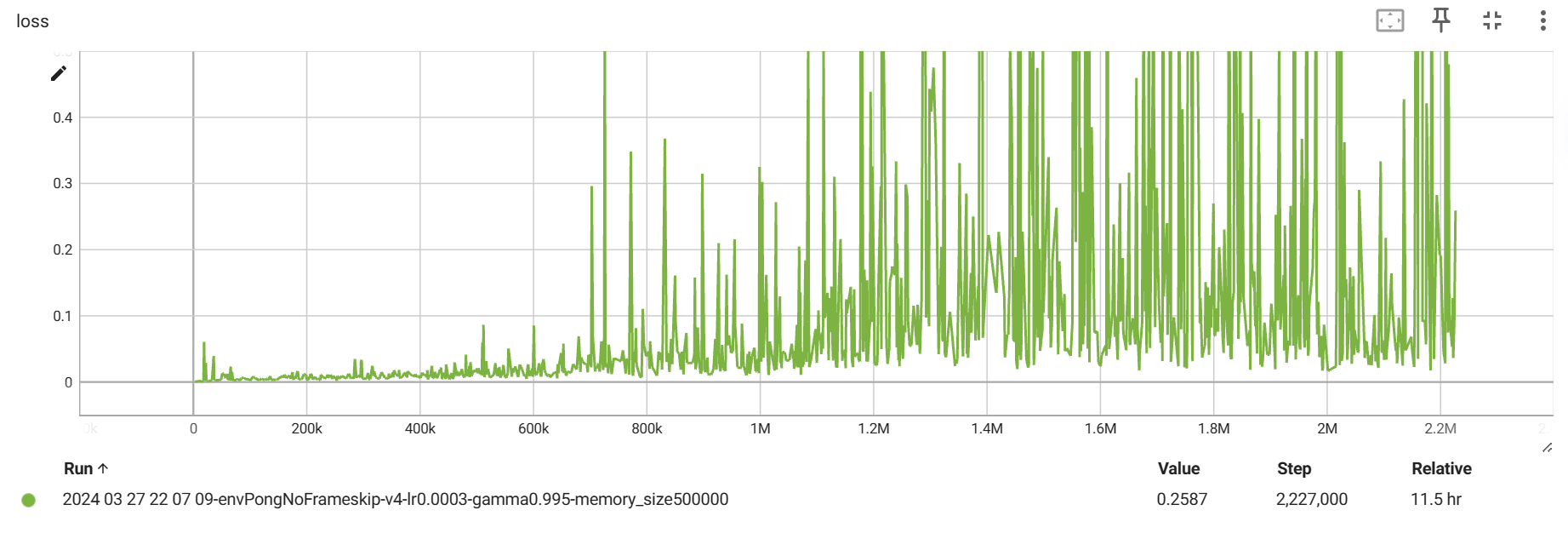
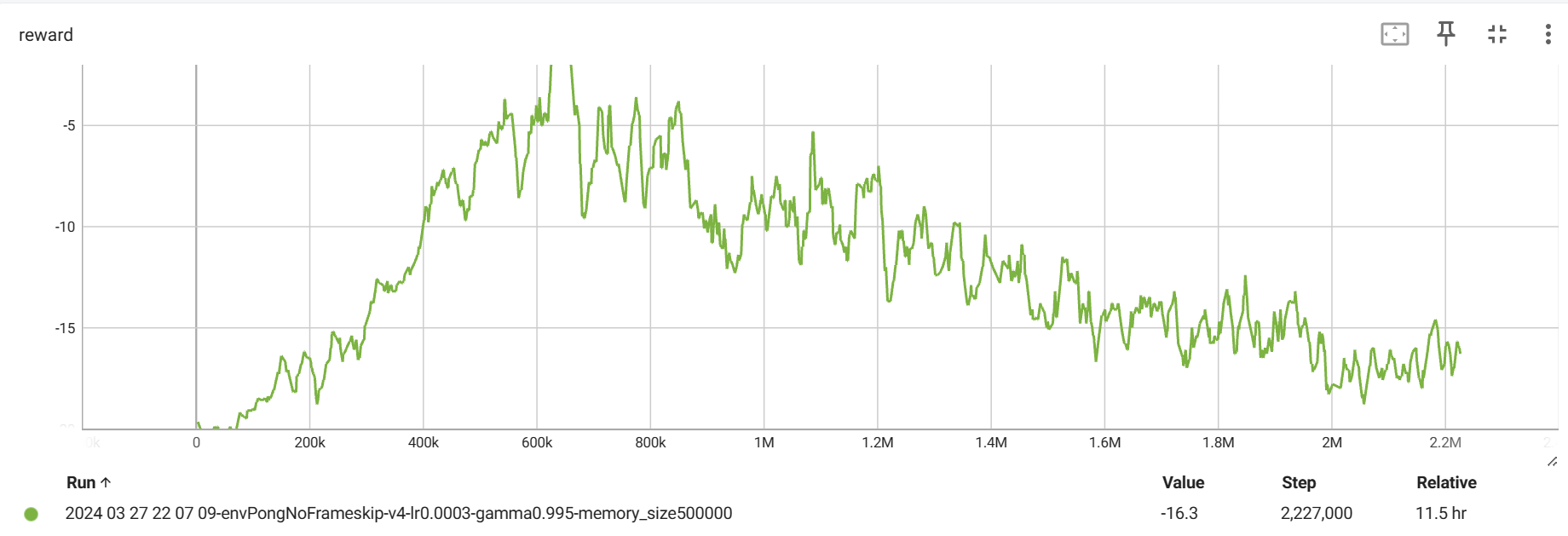
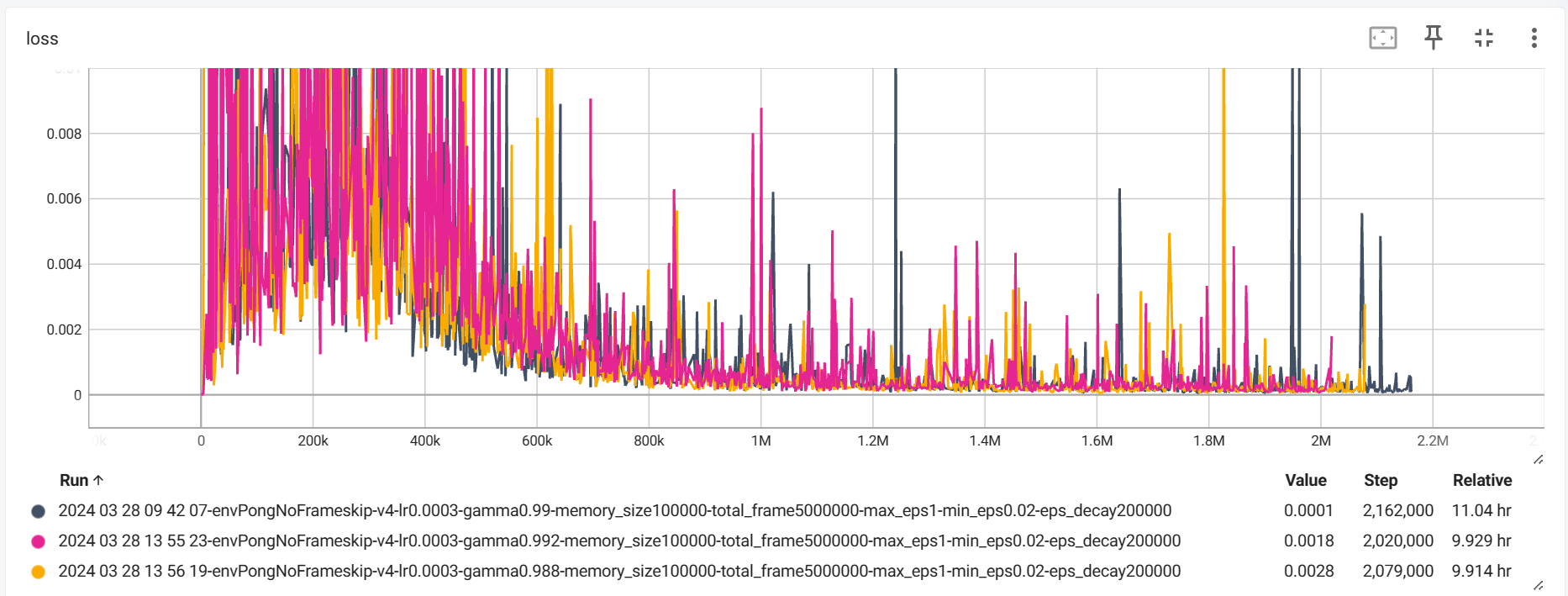
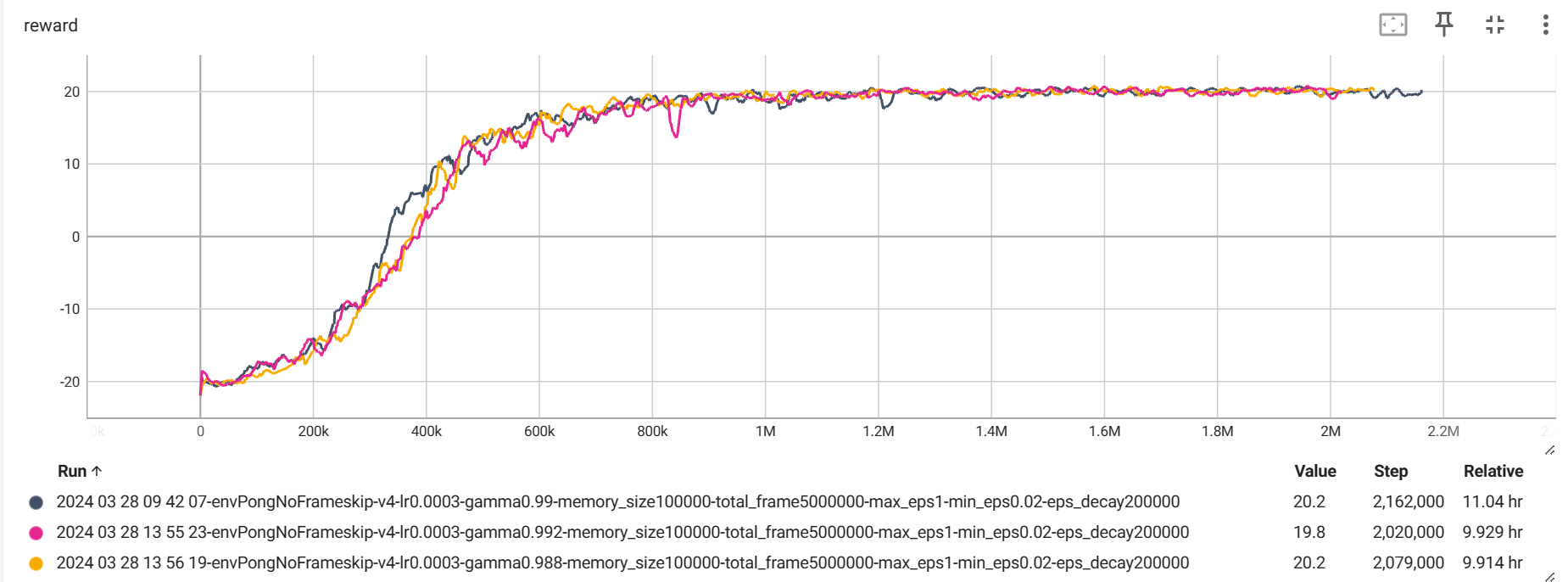
其次是,在每次调用 env.reset() 的时候,返回的四个参数只有第一个是图片信息,其他的都不是,应该使用 state = env.reset()[0] 来获取。
下面给出正确的环境配置:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
defmake_env(env_name): """ Create and configure an environment for reinforcement learning. Parameters: - env_name (str): The name of the environment to create. Returns: - env (gym.Env): The configured environment. """
classReplayBuffer: """ A replay buffer class for storing and sampling experiences for reinforcement learning. Args: size (int): The maximum size of the replay buffer. Attributes: size (int): The maximum size of the replay buffer. buffer (list): A list to store the experiences. cur (int): The current index in the buffer. device (torch.device): The device to use for tensor operations. Methods: __len__(): Returns the number of experiences in the buffer. transform(lazy_frame): Transforms a lazy frame into a tensor. push(state, action, reward, next_state, done): Adds an experience to the buffer. sample(batch_size): Samples a batch of experiences from the buffer. """
defforward(self, x): """ Forward pass of the DQN. Args: x (torch.Tensor): Input tensor. Returns: torch.Tensor: Output tensor. """ x = F.relu(self.conv1(x)) x = F.relu(self.conv2(x)) x = F.relu(self.conv3(x)) x = F.relu(self.fc4(x.reshape(x.size(0), -1))) returnself.fc5(x)
from utility.NetWork import NetWork from utility.ReplayBuffer import ReplayBuffer import torch import torch.optim as optim import torch.nn.functional as F import numpy as np import random
classAgent: """ The Agent class represents a Deep Q-Network (DQN) agent for reinforcement learning. Args: in_channels (int): Number of input channels. num_actions (int): Number of possible actions. c (float): Exploration factor for epsilon-greedy action selection. lr (float): Learning rate for the optimizer. alpha (float): RMSprop optimizer alpha value. gamma (float): Discount factor for future rewards. epsilon (float): Exploration rate for epsilon-greedy action selection. replay_size (int): Size of the replay buffer. Attributes: num_actions (int): Number of possible actions. replay (ReplayBuffer): Replay buffer for storing and sampling experiences. device (torch.device): Device (CPU or GPU) for running computations. c (float): Exploration factor for epsilon-greedy action selection. gamma (float): Discount factor for future rewards. q_network (DQN): Q-network for estimating action values. target_network (DQN): Target network for estimating target action values. optimizer (torch.optim.RMSprop): Optimizer for updating the Q-network. Methods: greedy(state, epsilon): Selects an action using epsilon-greedy policy. calculate_loss(states, actions, rewards, next_states, dones): Calculates the loss for a batch of experiences. reset(): Resets the target network to match the Q-network. learn(batch_size): Performs a single learning step using a batch of experiences. """
defget_action(self, state, epsilon): """ Selects an action using epsilon-greedy policy. Args: state (torch.Tensor): Current state. epsilon (float): Exploration rate. Returns: int: Selected action. """ if random.random() < epsilon: action = random.randrange(self.num_actions) else: q_values = self.q_network(state).detach().cpu().numpy() action = np.argmax(q_values) del q_values return action
defcalculate_loss(self, states, actions, rewards, next_states, dones): """ Calculates the loss for a batch of experiences. Args: states (torch.Tensor): Batch of states. actions (torch.Tensor): Batch of actions. rewards (torch.Tensor): Batch of rewards. next_states (torch.Tensor): Batch of next states. dones (torch.Tensor): Batch of done flags. Returns: torch.Tensor: Loss value. """ tmp = self.q_network(states) rewards = rewards.to(self.device) q_values = tmp[range(states.shape[0]), actions.long()] default = rewards + self.gamma * self.target_network(next_states).max(dim=1)[0] target = torch.where(dones.to(self.device), rewards, default).to(self.device).detach() return F.mse_loss(target, q_values)
defreset(self): """ Resets the target network to match the Q-network. """ self.target_network.load_state_dict(self.q_network.state_dict())
deftrain(self, batch_size): """ Performs a single learning step using a batch of experiences. Args: batch_size (int): Size of the batch. Returns: float: Loss value. """ if batch_size < len(self.replay_buffer): states, actions, rewards, next_states, dones = self.replay_buffer.sample(batch_size) loss = self.calculate_loss(states, actions, rewards, next_states, dones) self.optimizer.zero_grad() loss.backward() torch.nn.utils.clip_grad_norm_(self.q_network.parameters(), max_norm=20, norm_type=2) self.optimizer.step() return loss.item() return0
main.py实现命令行参数处理
在main中,使用如下方式处理参数:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
if __name__ == '__main__': parser = argparse.ArgumentParser() parser.add_argument("--env_name", type=str, default='PongNoFrameskip-v4', help="Name of the environment") parser.add_argument("--gamma", type=float, default=0.99, help="Discount factor") parser.add_argument("--lr", type=float, default=3e-4, help="Learning rate") parser.add_argument("--memory_size", type=int, default=100000, help="Size of the replay buffer") parser.add_argument("--total_frame",type=int,default=5000000,help="Total number of frames to train") parser.add_argument("--eps-max",type=float,default=1,help="Max epsilon value") parser.add_argument("--eps-min",type=float,default=0.02,help="Min epsilon value") args = parser.parse_args() epsilon_begin = args.eps_max epsilon_end = args.eps_min train(env_name=args.env_name, learning_rate=args.lr, gamma=args.gamma, memory_size=args.memory_size, total_frame=args.total_frame)