
RLHF
综述
这个方法的基本想法就是,我们在强化学习的过程中,可以引入人来打分,避免训练出来的情况不符合预期,更符合实际情况,其大致的流程是: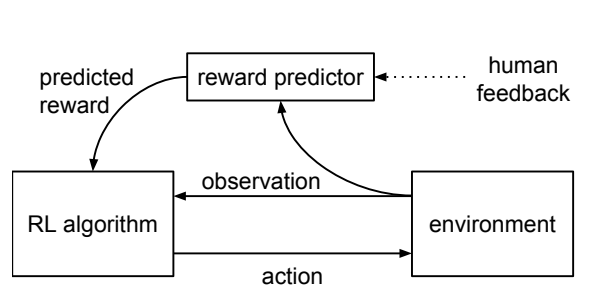
符号定义
这里相比于传统的强化学习是状态-动作,这里假定的环境是在时间
定义一条轨迹的某个片段是由一系列的观察和动作构成的,即
不同于传统强化学习里面环境直接反馈一个Reward回来,这里假设的是人类能够区分不同轨迹之间的优劣,换言之人类能够给出一个偏序,即判定:
评价一个RLHF的算法
定量
如果说人类给出评价的标准是基于一个可以定量的价值函数
产生的那么最后我们只需要看这个Agent是否按照 RL 的标准最大化了
定性
如果不是能够清晰量化的评判标准,那么就只能靠人类根据感受进行评判了
关于人类选择的记录
这里将人类的一个选择记录为
- 人类认为某个选择更优,则将对应的
置位为 - 人类认为两个选择等同,则
将独立采样 - 人类认为不可分辨则该样本不会出现在数据库中
最终把所有的数据放在一个数据库中
如何拟合Reward
如果认为这里的 Reward 函数昭示了人们选择动作的倾向,那么人类选择片段的倾向应该是指数的加权和,即
那么对于价值函数
以此来更新Reward
All articles in this blog are licensed under CC BY-NC-SA 4.0 unless stating additionally.