
Application Layer
HTTP
HTTP 的全程是超文本文件传输协议,即 HyperText Transfer Protocol 用于传输网页等超文本信息。
一个常见的网页(Webpage)主要由以下的东西组成:
- HTML文件
- JavaScript脚本
- CSS层叠样式表
- JPEG等其它资源文件
而HTTP的主要功能就是向客户机正确提供这些文件
URL
URL是输入在浏览器里面用来访问互联网资源的地址,其格式形如:
1 | http://www.someSchool.edu/someDepartment/picture.gif |
这里面主要包含一下几个部分:
http://指明协议,可能包含http、https等www.someSchool.edu被称为hostname即主机名,是指提供该服务的主机名称someDepartment/picture.gif是路径名(Path name) 描述希望获取的资源的位置
这个URL这里是可以整花活的,例如你可以在桌面创建一个 a.txt 的文件,然后在浏览器中输入 file:///C:/Users/Username/Desktop/a.txt 记得把这里面的username换成你自己的用户名,按下回车就可以在浏览器中查看本地的文件了
解释一下这里为什么
file后面是三个/其实你也可以写成file://localhost/的,只是这里省略了
另外,这里的hostname后面可以跟端口,例如:
1 | http://www.ericli.vip:8080/ |
这个URL的含义就是使用HTTP协议访问主机 www.ericli.vip 的 8080 端口
Non-Persistent and Persistent Connections
HTTP有两种连接方式,一种是 Persistent 另一种是 Non-Persistent 这两种的区别就是 Non-Persistent 的链接每一次传输文件都需要重新建立一个 TCP 链接,需要重新花费 2RTT 的时间来握手,而 Non-persistent 的不会
http报文格式
request
一个http头的形式如下:
1 | GET /somedir/page.html |
其规约如下: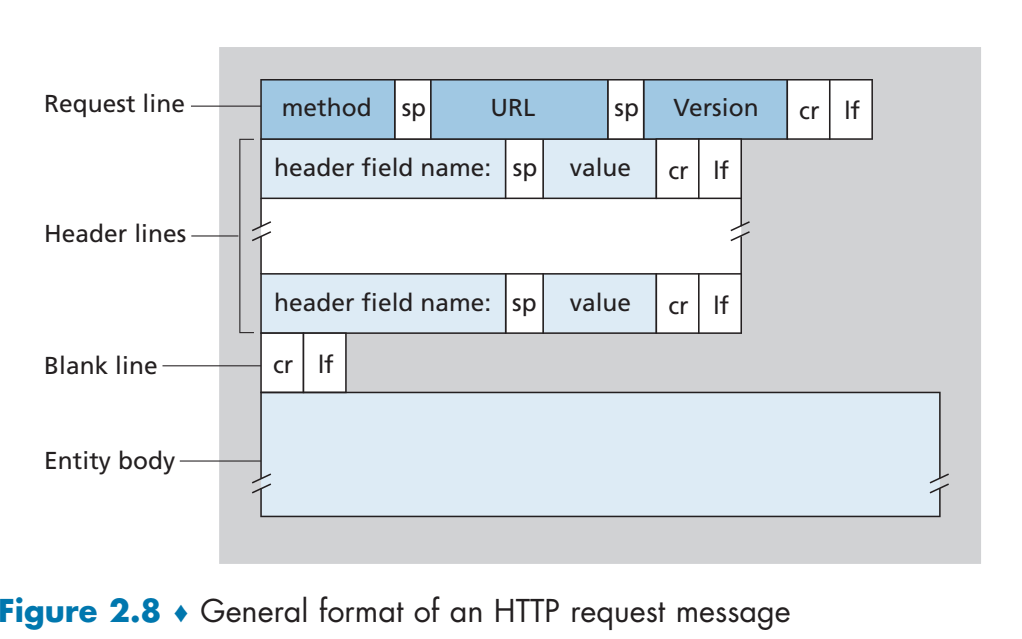
这里面每个键的含义如下:
method: 包括GET、POST、HEAD、PUT和DELETE其中最常用的是GET用于获取一个网页URL: 这里的URL字段就只有路径了,因为hostname后面有专门的字段保存Version: 就是这里的HTTP/1.1表示使用的HTTP版本号Host: 这个键的位置填的是主机名称Connection: close这一条表示这个http链接预期是non-persistent的User-agent: Mozilla/5.0这里表示的是浏览器版本Accept-language: fr表示预期收到的语言版本
而在这个例子中,因为方法是GET所以不需要写Entity body字段,但是如果方法是POST之类的,就需要根据用户的输入填写Entity body字段
response
一个http的回文如下:
1 | 200 OK |
其形式规约为: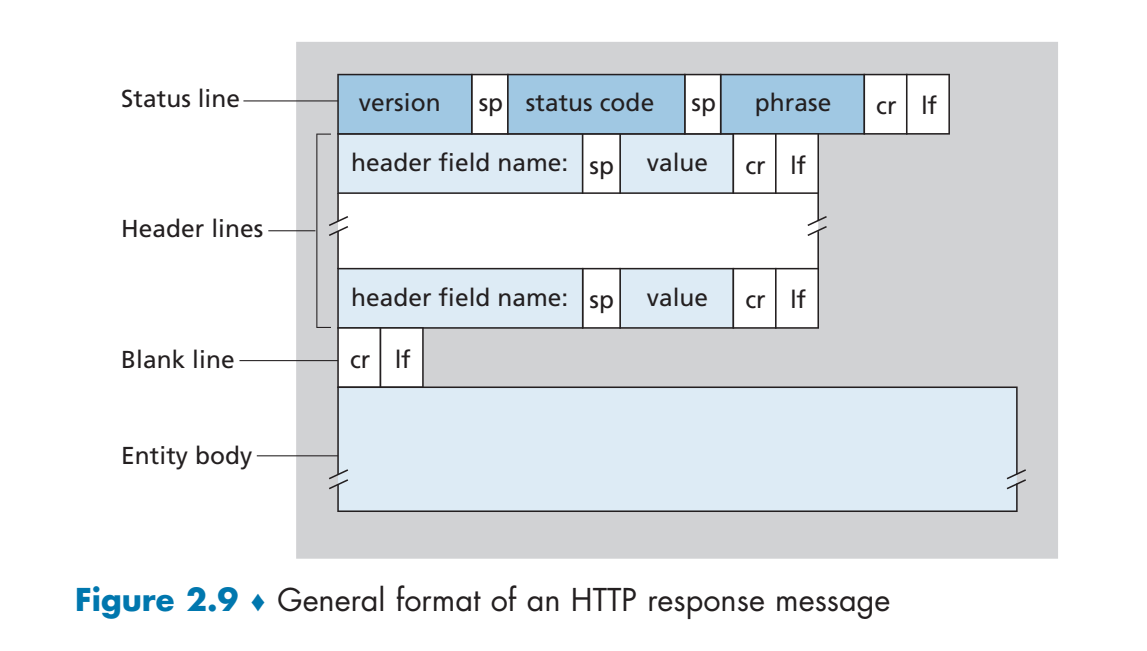
这里面的头的含义如下:
HTTP/1.1 200 OK表示版本号是HTTP/1.1状态码为200 OK即这个请求找到了服务器并请求到了正确的内容Connection: close表示server在发送这条http消息之后就会关闭 注意这里和上面请求的区别Date: Tue, 18 Aug 2015 15:44:04 GMT注意,这里表示的是 这个http回复被服务器创建并发送的时间Server: Apache/2.2.3 (CentOS)表示服务器的版本信息Last-Modified: Tue, 18 Aug 2015 15:11:03 GMT表示这个实体上一次被修改的最后时间Content-Length: 6821表示内容的长度,单位是bytesContent-Type: text/html表示返回实体的类型
这里的状态码有以下的可选情况:
200 OK成功找到了想要的内容并正确返回301 Moved Permanently表示网页的内容被永久移动到了新的地址,此时会返回一个Location:字段标识出新的地址400 Bad Request表示这个请求没有被正确识别,服务器无法做出响应404 Not Found表示这个请求的实体无法找到505 HTTP Version Not Supported表示服务器无法支持这个版本的 http 服务
Web caching
这个方法的本意就是,你每次请求一个资源的时候没必要都去网站的服务器上请求,可能在局域网内部做一个缓存系统,那么每次请求一个资源的时候,流程如下:
- 浏览器先和
cache server握手建立连接并向cache server发送请求 Web cache会先检查本地有没有这个资源的拷贝如果有,就把这个资源直接发回去- 如果这个
Web cache没有该资源,那么就会和原始的服务器建立请求并请求该资源 - 当
web cache收到资源的时候,会拷贝一份,留存本地并发送给浏览器
Conditional GET
如果 web cache 在储存了副本之后,原始的资源发生了更改,那么会造成不一致,所以这个时候有一个机制可以询问原始的server有没有发生变化,即 web cache 会发送一条请求:
1 | GET /fruit/kiwi.gif |
这个时候如果没有发生更改,server会回复:
1 | 304 Not Modified |
表示没有更改,否则会重发这个资源
SMTP
发邮件的流程如下: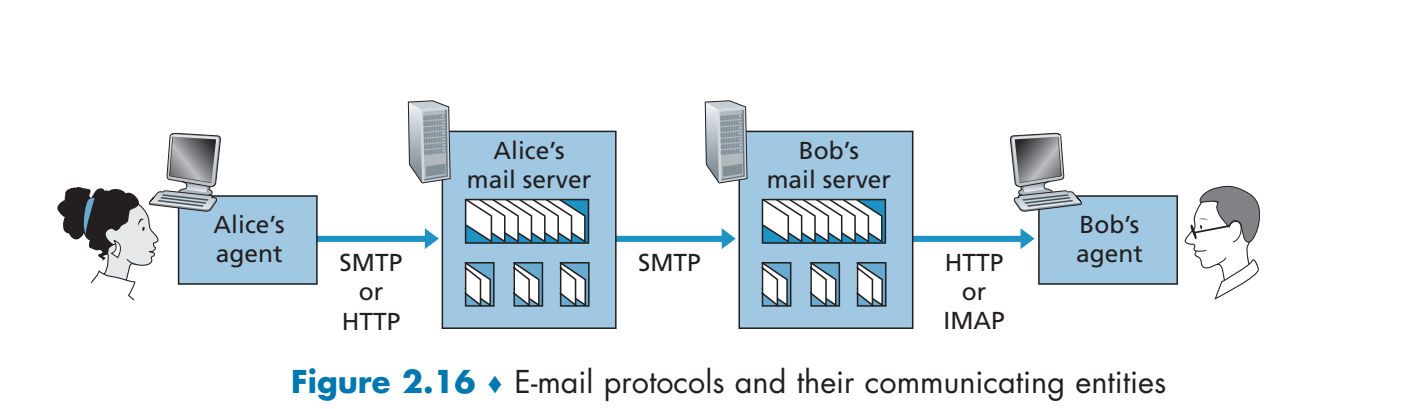
DNS
DNS记录
一个DNS记录是一个四元组,内容是 (Name, Value, Type, TTL) 其中的TTL表示
A记录:记录的是hostname的IP地址NS记录:这种记录里面的Name里面放的是请求的域名,而Value键里面放的是知道该域名IP地址的DNS服务器名称,例如(foo.com, dns.foo.com, NS)CNAME记录:这里面记录的name是alias的别名,例如(foo.com, relay1.bar.foo.com, CNAME)这里面的relay1.bar.foo.com是foo.com的规范名称MX记录:这里面的value是这个域名下面的邮箱的规范名,例如:(foo.com, mail.bar.foo.com, MX)
TBD
P2P
一个P2P网络的形式如下: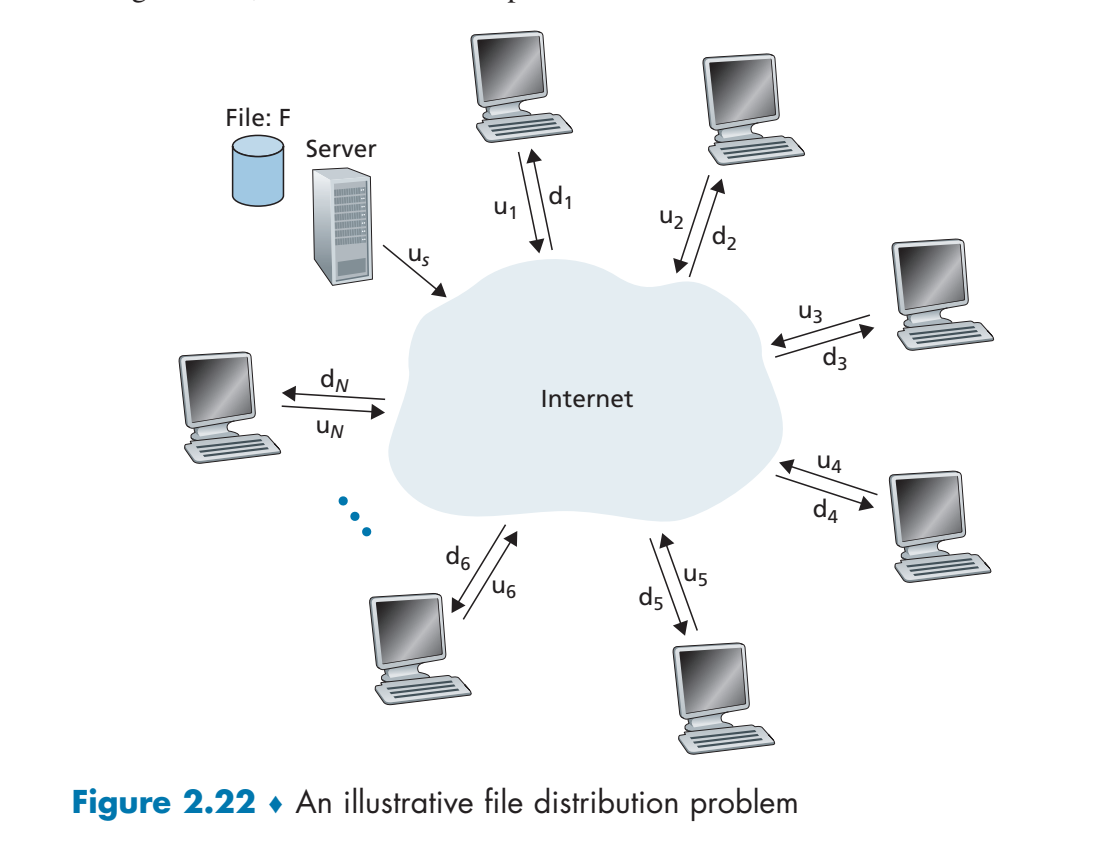
这里面的
peer之间不相互传输
在这种情况下,服务器需要向所有的机子传输数据,记
p2p的结构
- 最开始的时候,只有服务器持有这个文件,那么服务器上载的时间至少需要
- 所有client都接收,至少需要
的时间 - 考虑这个网络中所有终端的上载能力,总共需要上载
大小的数据,而所有终端都上载的时候,总的速率为 所以此时最少的分发时间为
考虑以上三点,那么在p2p网络结构中,分发该文件的耗时为:
而下界是可以取到的