
FLA Lab Report | 自动机大作业实验报告
设计思路
整体上我的程序分为如下几个步骤:
- 读取命令行参数
- 如果有
-h就输出帮助信息并退出 - 如果带有
-v或者--verbose参数就把fla结构体中对应的值设为true
- 如果有
- 根据命令行输入的文件后缀,判定运行的模拟类型,并记录到fla结构体中
- 读取文件的内容,加载到对应的结构体中
- 根据上一步判定的模拟器类型,把fla结构体传给对应的模拟器
PDA模拟器
对于pda模拟器,我的设计如下:
我用的面向对象的方法,每一个状态都被封装成了一个类,模拟器保存了一个迭代器指向当前的状态。每个状态提供一个 pair<bool,pair<int,string>>get_transition(char input, char stack_top) 方法,传入当前的字符、栈顶符号,返回 (是否成功,下一个状态的编号,栈顶压入符号)
具体的运行方式如下:
- 使用
compile()函数可以编译一个pda模拟器,经历如下步骤:- 传给Lexer,按照行给整个传入的文件进行划分,并丢弃所有分号后面的内容。
- Lexer将每一行传给
get_statement()函数,该函数根据语法规则,依次判定每一行是否合法,以及每一行属于整个描述文件的哪一个部分,生成一个PDA_STATEMENT结构体,里面包括了这个声明的类型,以及去掉格式之后的有效内容 PDA_STATEMENT会被传到parse_pda_statement里面,根据statement的类型,进行创建状态、添加对应的转移函数、初始化栈符号等等
- 使用
bool run(string)函数进行模拟,首先根据上一步compile的结果,初始化一个pda,然后根据输入一步步模拟就行了。
TM模拟器
TM的状态我采用的是和上面的PDA相同的设计,也是面向对象,这里主要讲一下我对于tape的设计
对于每一个纸带包含如下成员:
1 | list<char> tape_; |
其中使用一个 list<char> 来记录纸带上的内容,迭代器 head_ 用于记录当前纸带头所在的位置,而zero_ 迭代器用于记录纸带的坐标0的地方。纸带对外提供获取当前纸带记录、头字符、起始点相对坐标这些功能
TM的解析采用了和PDA相同的设计模式:
- 首先,Lexer会将整个tm的内容拆分行,这里跟前面的PDA的区别是,这里我直接根据每一行的特征,判断属于哪一个组成成分,并校验格式报syntax error
- 然后每一行传给parse函数,给图灵机添加对应的状态、添加转移函数
这里有一个需要注意的地方,就是星号通配符的匹配。这里最开始我没有想到怎么处理,后面我觉得直接在每一个state对象匹配转移的时候,进行特判处理。
对于verbose模式,输出其实没什么特别的,主要有两个难点:如何计算每一个字符的序号,如何对齐。
对于计算字符的序号,之前的tape部分提到过,我会返回zero_迭代器相对于head的位置,那么根据这个位置,就可以计算出初始坐标在打印字符里面的相对坐标了
对于第二个问题,我认为核心科技就是:
1 | int blank_size = std::to_string(idx).size(); |
通过这个可以获取坐标的长度,用这个来算需要多少个空格就很简单了
实验完成度
本次实验完成了手册中要求的所有必做项目
PDA正常的模拟

如图所示,对于接受、拒绝以及非法字符都能正确处理
PDA的语法检测
实现了缺失括号的检测: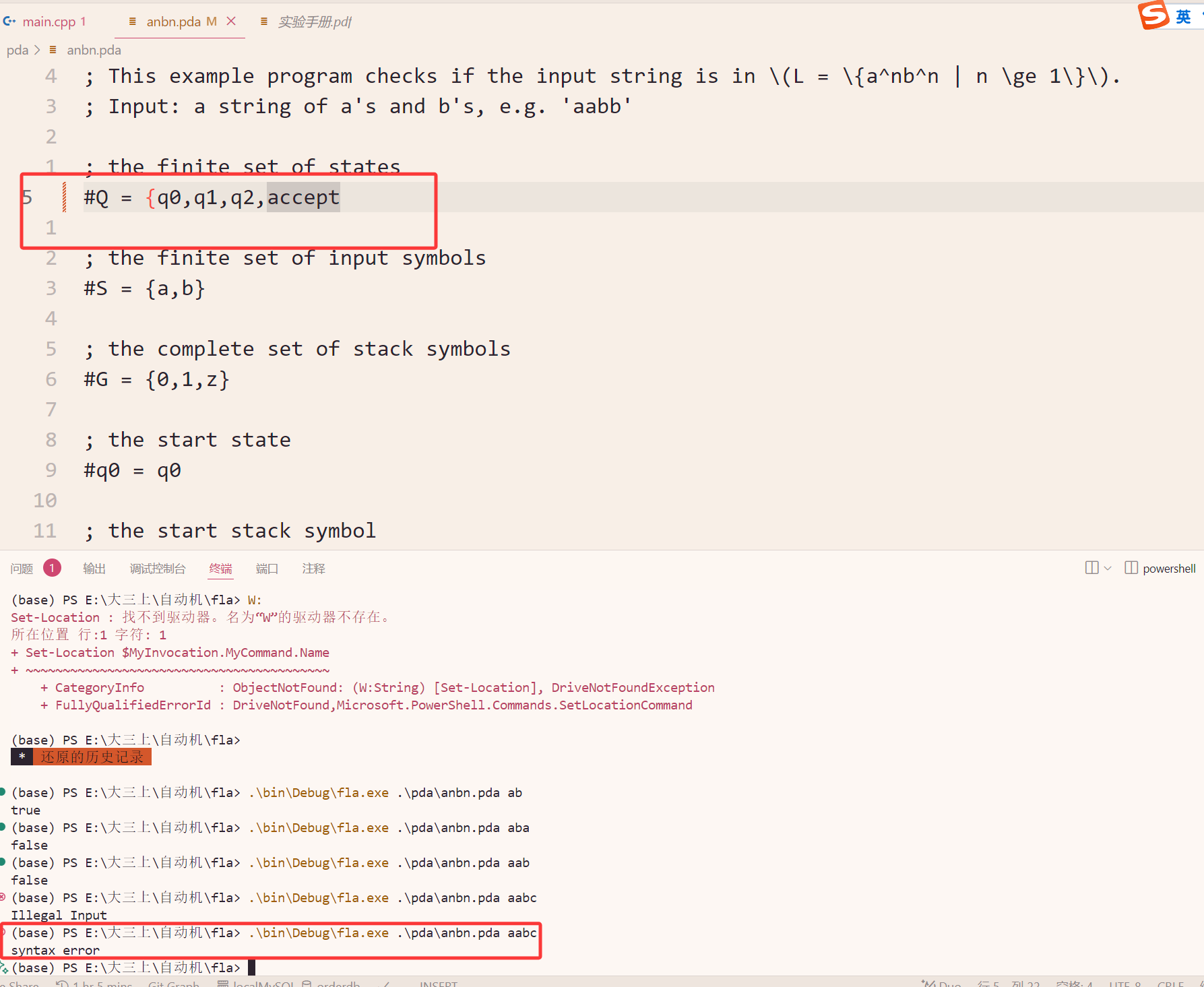
非法转移的检测: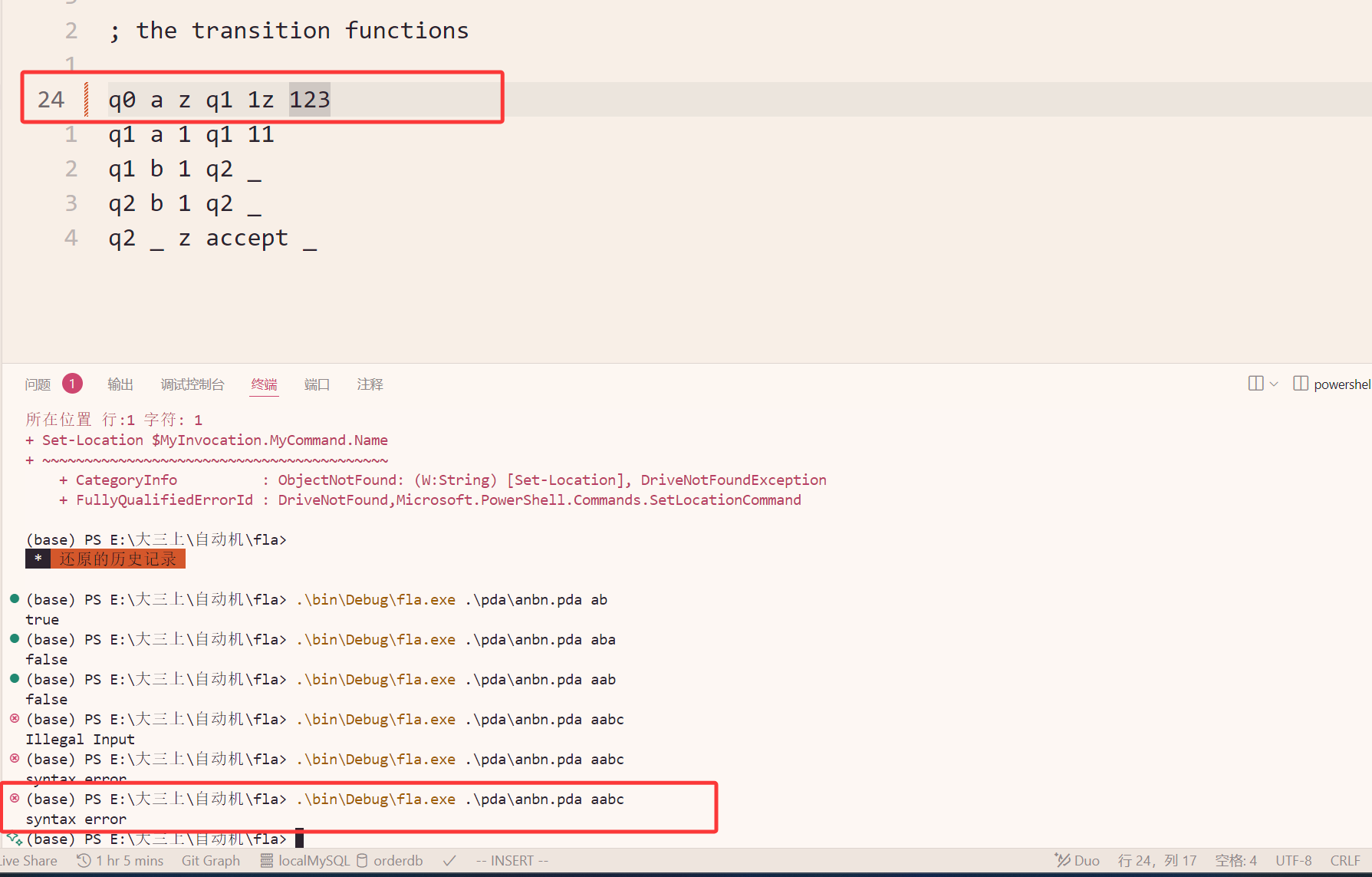
缺失空格的检测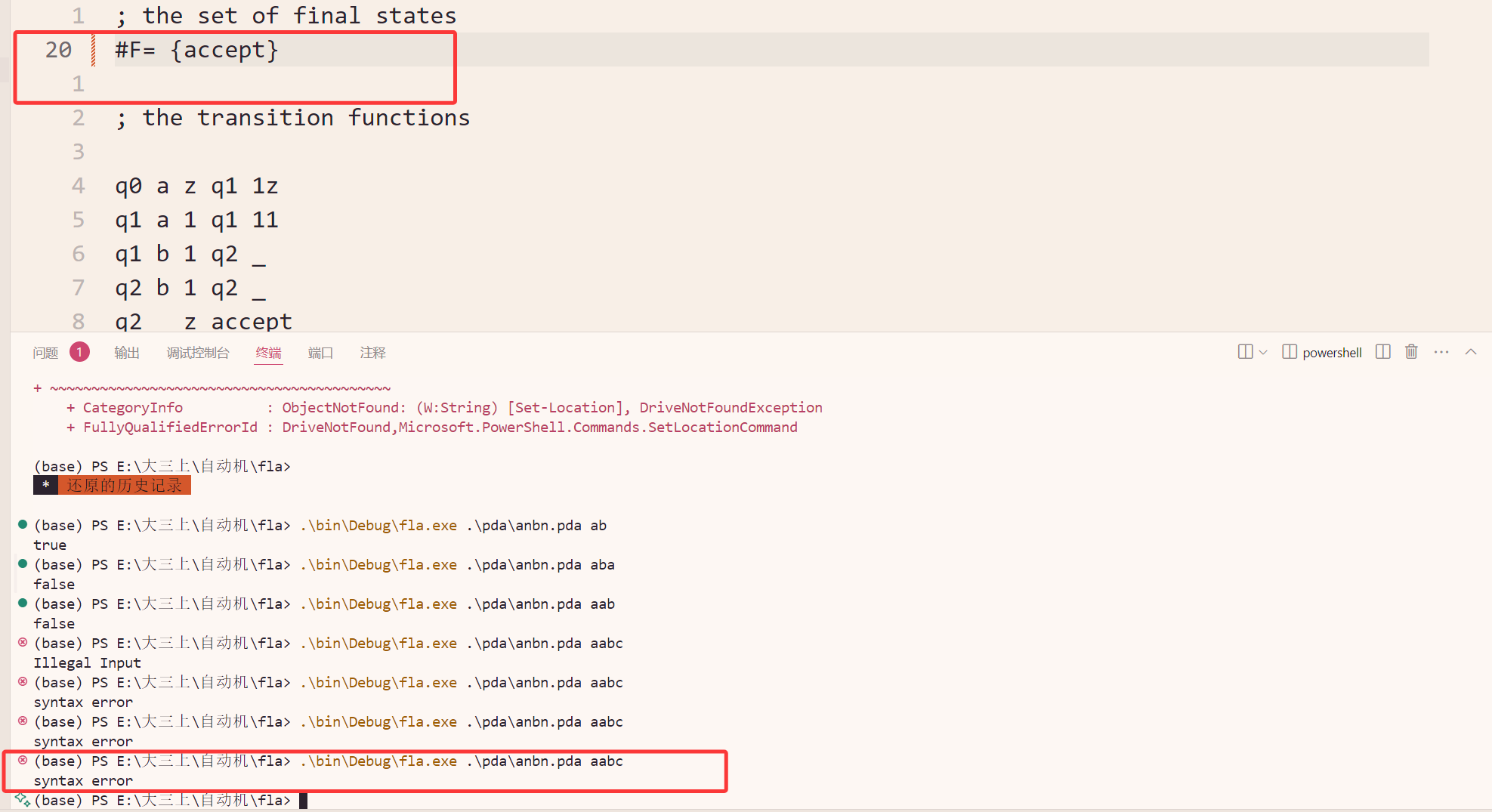
TM的正常模拟

TM的错误输入verbose模式
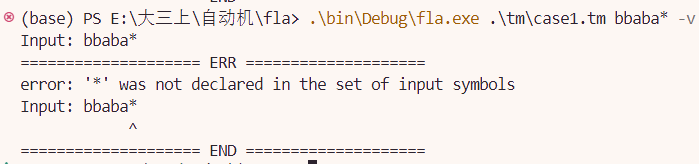
TM模拟运行的verbose模式

TM的语法检测
实现了缺失括号检测: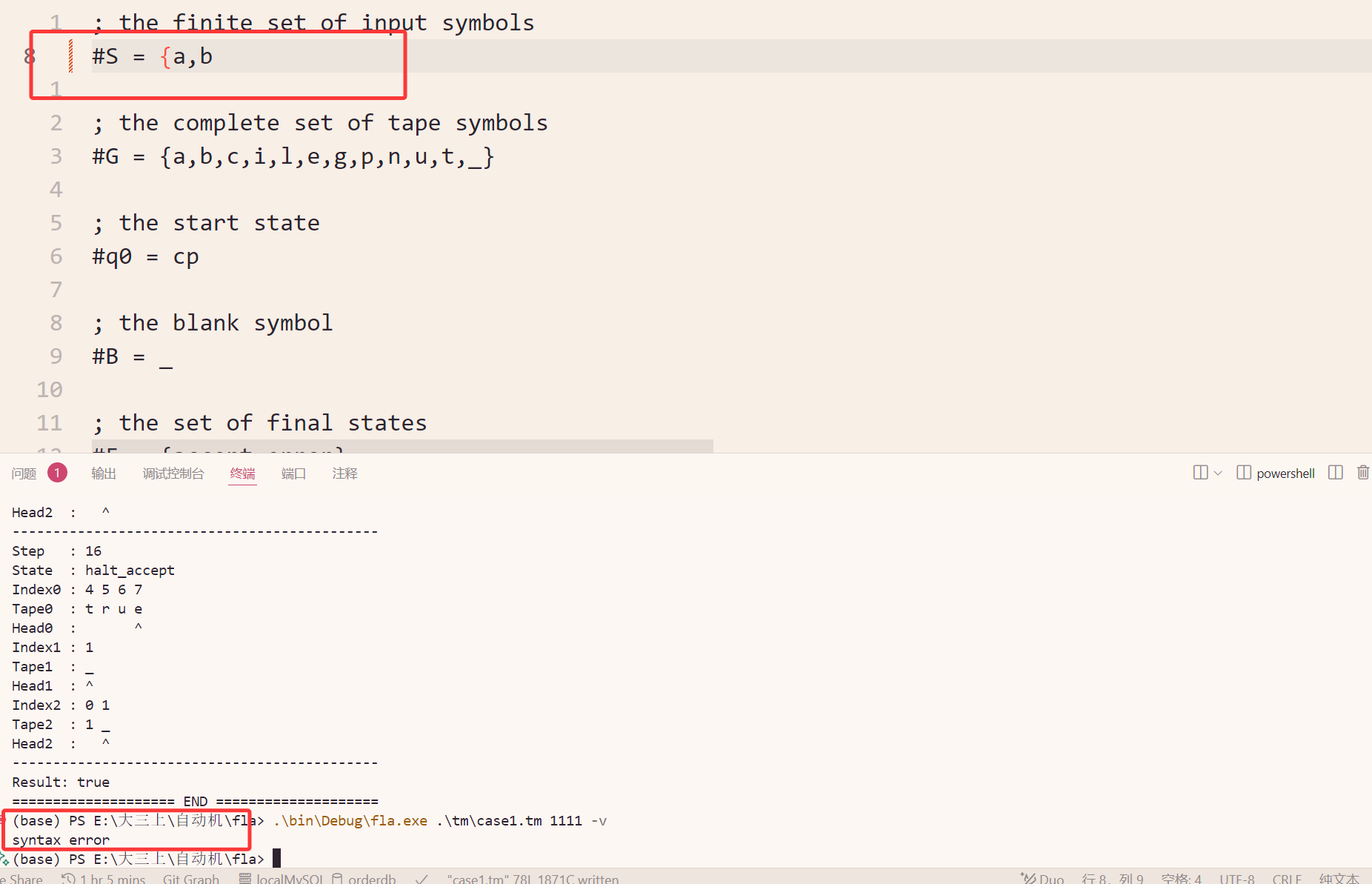
错误转移检测:
非法纸带数量检测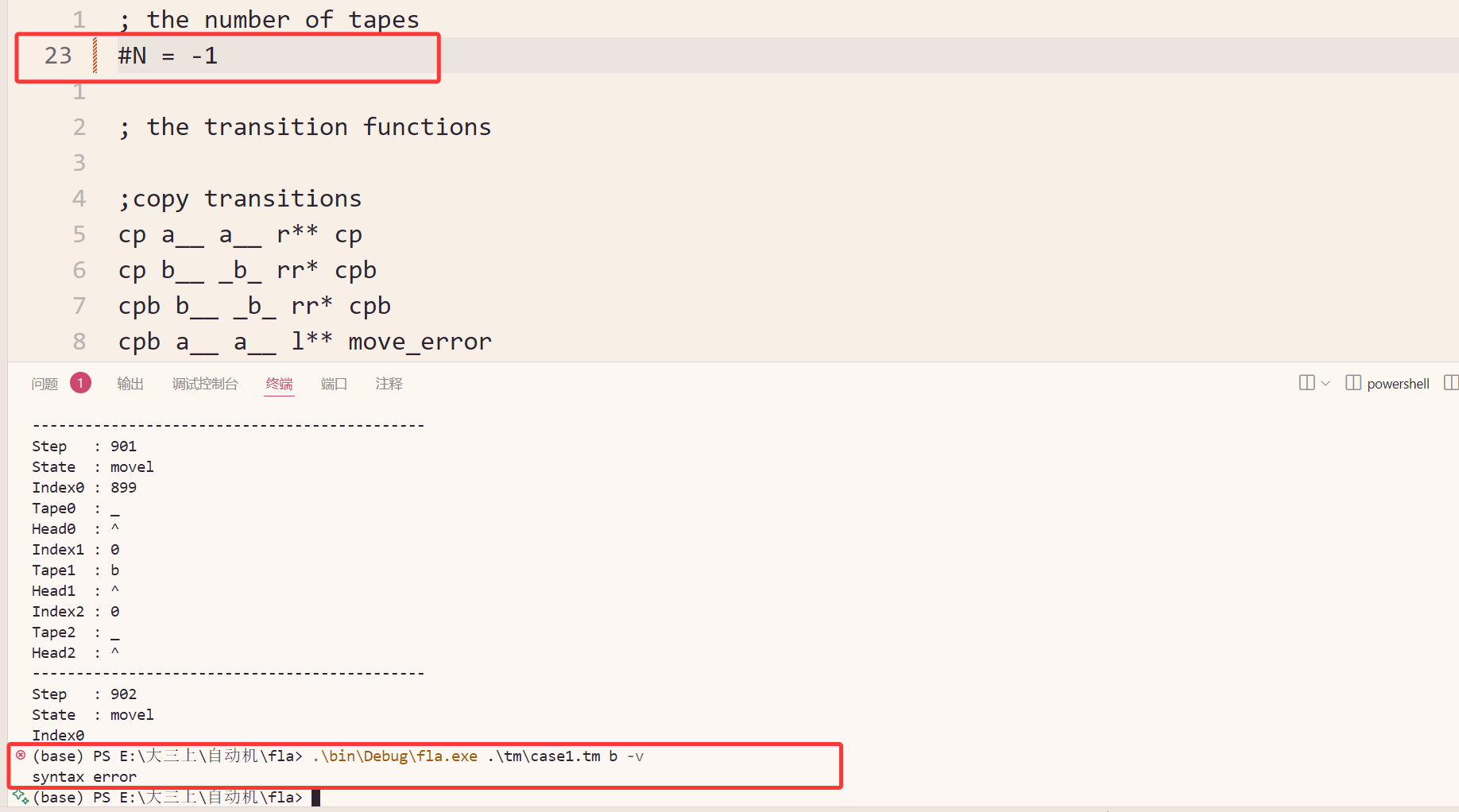
实验中遇到的困难
主要的困难就是,这里使用面向对象导致整个程序过于冗长,有1400多行,如果抛弃面向对象直接对字符串做处理应该能简单不少。
总结感想
下次写这种大工程,应该考虑清楚需求,改一下架构再写,不用硬套范式,避免屎山代码。
建议
无